Permissions for AI Use Cases
ai airbyte data data-engineering engineering llm rag
2025-01-14 - Originally posted at https://airbyte.com/blog/permissions-for-ai-use-cases
↞ See all posts


Our visualization for bringing permissions to your AI application.
Overview
When building AI Pipelines, syncing who has access to the content is almost as important as syncing the content itself. In traditional data warehouse work, access to the tables in the warehouse is controlled by humans on the data/analytics team. If the viewer’s role is appropriate, they can view the table - e.g. the finance team can view the "purchases" table, but not the full “users” table, which contains PII. However, it will be common for AI applications to work against datasets of content, not just data - including text, videos, etc. This content is guaranteed to contain PII, sensitive business or financial information, and other “private” information. To that end, we can’t use the same human-controlled permission model as before, granting all users the same access to the “Google Drive Documents” table - their individual roles and access need to be preserved. Furthermore, when building secure AI applications, it is imperative that the context provided to the LLM only includes content that both the machine and end-user is allowed to see - relying on the AI itself to guard sensitive information has been regularly shown to be a flawed approach. To this end, when thinking about AI applications, a multi-stage permission model will be needed:
- Extracting permission, role, and identity along with the content
- Filtering content into role-specific collections
- Mapping Identities to streams
- Making all requests to the context collection with the appropriate identity
Not every source provides the ability to extract identities, roles, and permissions at the level we would like. This is why a 2-phase approach is needed, to allow some level of access control even for the worst sources.
A note on pre vs post access lookup in the system of record
The most secure way to check access would be to query the system or record (e.g. Google Docs APIs) at read time to confirm that the user still maintains access to the original document. This is a great approach when the user is requesting access to an individual resource (and the system of record is both performant and has high uptime). However, for AI use cases, which operate on either multiple resources (RAG) or aggregates (text-to-SQL), spending the time to look up every possible resource will be too high, and likely rate-limited. Therefore, we need to cache this information ahead of time to make it available to us at query time. This will introduce a few necessary bad properties into the system, notably permission lag (you might be able to see an item you shouldn’t see any more) and flattening (the nuance of the groups and ACLs in the source system will be lost and made more coarse)
To mitigate the lag issue, we will be allowing users to sync the permission data/stream more often than the content itself.
To mitigate the flattening issue, the context identity streams should not be used as a system of record, but rather as a metadata to the data stream.
Extracting permission, role, and identity along with the content
Consider a Google Drive source. We will want to ingest all the presentations and documents available for our application, and maintain which of those documents each user has access to. Google Drive does provide APIs to load all of this information, so we can produce 2 streams of data:
- Files: The documents themselves in textual (e.g. markdown) format we need for our AI applications, and related metadata. Included in this metadata are the IDs of users and groups who have access to it, as well as the file/bucket the content came from, created and modified timestamps, etc.
- Identities: The “unrolled” list of users who are members of each and every possible group in the domain.
The best sources will provide both of these streams. Each of these streams can be set to sync at different frequencies, and will likely be set to use different sync modes as well - Files will likely be incremental, but Identities will likely be full-refresh.
All File streams will gain the following properties:
allowed_identity_remote_ids(list[str])denied_identity_remote_ids(list[str])publicly_accessible(bool)
The job of unrolling group memberships is the job of the source, and the schema of the Idendites stream will at-least include:
remote_id(str)email_address(str)member_email_addresses(list[str])
Filtering content into role-specific collections
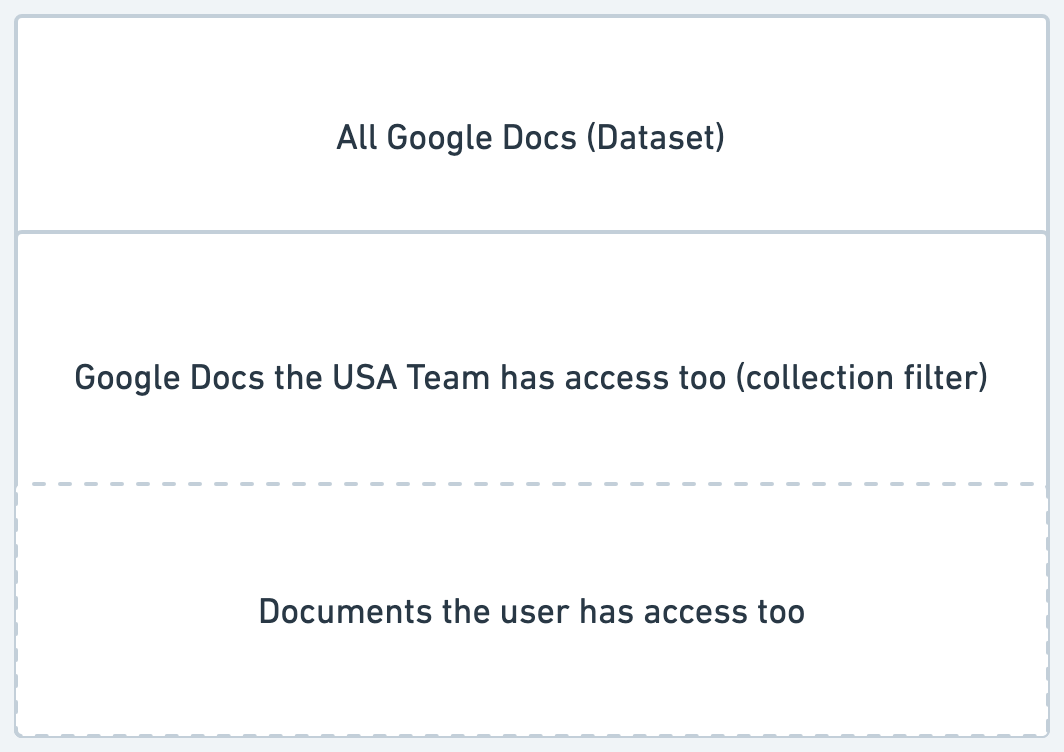
As an administrator of the ingestion pipeline, you may wish to use filters as a coarse way of adding role information to the dataset. For example, if your incoming dataset from Google Drive includes the original file paths of the documents, you may want to exclude any documents in the “exec” folder, as they are likely to be too sensitive. Or, you may want to split your dataset into “EU” and “USA” documents based on other pieces of metadata (e.g. folder name or group memberships), to provide limited or different information to different groups of users. This filtering step is especially useful when the source is not able to provide complete Identity and Role information - filtering can act as a stop-gap.
Mapping Identities to streams
If the source is able to provide Identity and Role information, we need to join the streams together. This is done by way of a “mapping”, joining (in the SQL-sense) all the user and role information to the original content record so that we have an easy way to query who can access each item. This will be duplicative of the data (adding storage cost) with the goal of producing a faster runtime looking (much like an index). We have decided to use Email Addresses as the shared unit of identity across all sources.
Making all requests to the context collection with the appropriate identity
It is finally time to use our data in an AI application. As the application/agent developer, you will choose to hit the RAG/Chat completion/Search/Aggregation APIs including a user’s email address or not. If an email address is provided, all the information provided back to you & the LLM will be further filtered to what they are allowed to access and the filtering provided by the context collection itself. Otherwise, they will have access to all the content in the (filtered) collection:

I write about Technology, Software, and Startups. I use my Product Management, Software Engineering, and Leadership skills to build teams that create world-class digital products.
Get in touch