The Components of an AI Context Pipeline
ai airbyte data data-engineering engineering llm rag
2025-01-15 - Originally posted at https://airbyte.com/blog/the-components-of-an-ai-context-pipeline
↞ See all posts

Today, Airbyte is the best way to load data into your data warehouse or data lake. Whether your content comes from databases, files, or APIs, Airbyte can move your data quickly and reliably. Airbyte has built the largest connector catalog, and the tools to make your own, via our development kits or our low/no-code connector builder. The Airbyte platform runs in our cloud or your own datacenter. The Airbyte protocol and our orchestration engine are able to handle incremental syncs or full refreshes, across multiple generations of data. Airbyte is the right choice for doing data movement for data warehouses, like ELT.
However, the needs of modern AI applications, specifically those focusing on interacting with, providing context to, or augmenting LLMs, need more than what traditional data movement solutions can provide. This blog post aims to provide a taxonomy of the components of an AI Context Pipeline, and how it differs from existing ELT/ETL pipelines. Working backwards, the goal of an AI Data Pipeline is to produce a context collection for the LLM which will either provide documents for RAG search or Function Calling capabilities. The storage for this data looks less like a data warehouse (with multiple tables for different business objects which can be joined together on demand), and more like use-case specific tables with documents and metadata designed for hybrid search. Hybrid search means that you are able to both perform a vector/similarity search on the content (e.g. “Who are my customers in New York?” would return documents where users noted their address as “NYC”, because that is similar to “New york”), as well as traditional WHERE clause filtering on the data (e.g. where deal_stage=pending and customer_country=usa). So how do we get there?
The AI Data Pipeline
We believe that an AI Context Pipeline has 6 major steps: Extract, Normalize, Load, Build Context, Evaluate, and Consume. Each of these steps produce artifacts which are consumable, observable, and replayable, much like the various tables in a data warehouse medallion architecture. Each of these 6 major steps and their subcomponents can be modularized.
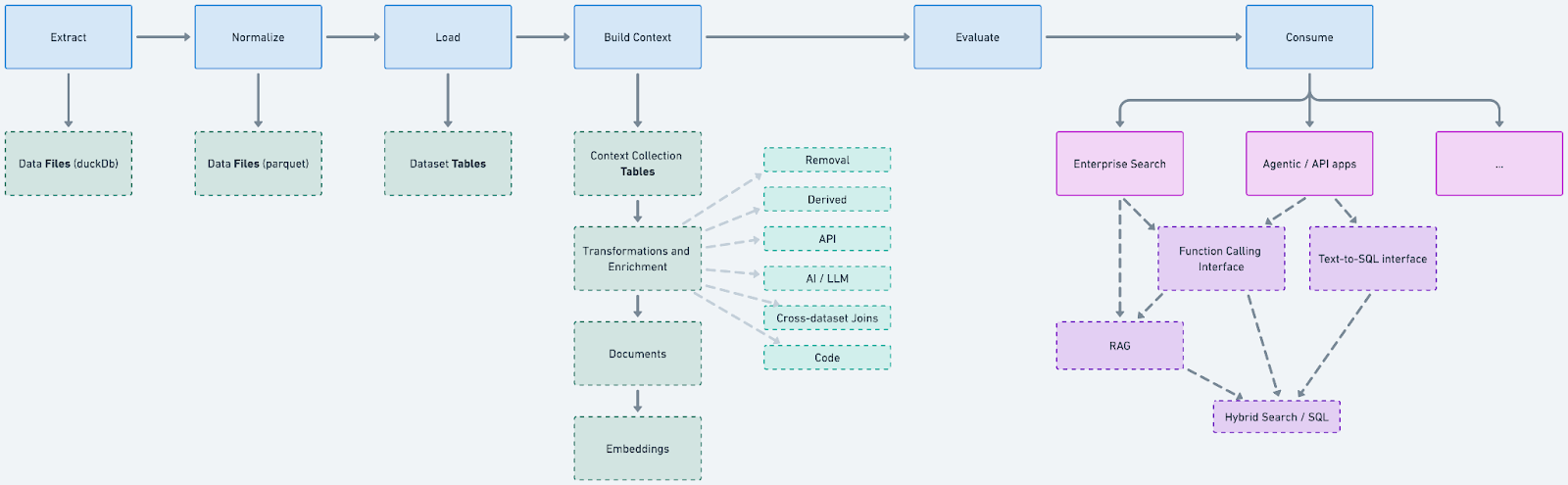
Step 1: Extract
This is Airbyte’s bread and butter, and building connectors while maintaining them is hard. In fact, we couldn’t do it without the largest open-source community of connector developers. API changes (both planned and unplanned), data-type bugs, rate limit problems, vendor outages, and handling authentication quirks are only some of the problems that Airbyte’s connector development teams solve. Airbyte also works with vendors to sync data incrementally whenever possible (e.g. syncing only the changes since last time), to be as fast and cost-efficient as possible. On top of that, there are questions of syncing strategy. For example, would this particular API source benefit from parallelism, or would that make things worse? Does this database support CDC replication, and if so, what’s the best way to implement it? We’ve learned that syncs are stateful (needing cursors, refresh tokens, etc) and produce a schema. Airbyte handles all of these things.
Airbyte’s AI pipeline leverages our existing connector catalog and syncing engine to robustly get your data out of source systems into the first stage of this pipeline. In addition to the above, there are 2 additional concepts that are important when thinking about AI use cases: dealing with unstructured/non-textual content, and permissions. Due to these new requirements, we are building custom blob-storage sources for our AI Pipeline that are different from the standard Airbyte sources.
Extracting Unstructured Data & Metadata
For AI use-cases, you need to get text from all of your sources. For APIs and databases, this is easy, but things get weird when object storage sources are involved (e.g. SFTP servers, S3 buckets, Google Drive, etc). Specifically, we are talking about the ability to read a directory of PDFs or Word documents, and extract the text contained within. This is sometimes called OCR, parsing, or simply reading unstructured documents. Airbyte has built expertise in this area over the past year and integrated this capability into our S3, Google Drive, and similar object-storage sources. When running sources in this mode, Airbyte will produce large textual records for each document found (e.g. PDF file), with the content converted to markdown. We find that markdown strikes the right balance between being machine and human consumable, maintaining enough of the semantic and layout information from the document (headers, links, etc), while still being performant and small. Along with the markdown version of the content, we’ll also extract metadata from the original source (original file name, mime information, etc). You’ll want to use this information in later steps in the pipeline.
Permissions and ACLs
In traditional data warehouse work, access to the tables in the warehouse is controlled by the humans on the data/analytics team. If the viewer’s role is appropriate, they can view the table. For example, anyone on the finance team can see the purchases table/mart, but they can’t see the whole customers table/mart. It’s likely that those data marts were produced by combining multiple source tables together, which in the source system, had a divergent permission model from what we want to accomplish in the data warehouse. So, because they don’t really relate, the permissions from the source system could be ignored as part of the extraction process and rebuilt later. This might not be the case in AI workflows.
When building secure AI applications, it is imperative that the context provided to the LLM only include content that both the machine and end-user is allowed to see. Relying on the AI itself to guard sensitive information has been regularly shown to be a flawed approach. To this end, when thinking about AI applications, a multi-stage permission model will be needed:
- Source permissions: What users or groups could originally see this content?
- Context collection permissions: What users or groups have access to this bundle of content?
An example might be helpful - Say we are ingesting content from Salesforce and we are building a copilot for our sales team to prepare for calls. Perhaps your sales team is divided regionally, and in Salesforce, AEs are limited to seeing information only within their own countries. It should follow that the deals each AE is allowed to ask the LLM about should follow those same rules in the copilot. That information could be reflected in your Salesforce configuration, and if so, we should include a list of groups that have access as metadata to each opportunity and contact we extract. But, that information is equally likely not to be available in the Salesforce API, so we’ll need to re-create it in our context collections. In that case, we could use the contact’s country code to split the data we have into USA and EU collections, and then grant access to each that way.
Modeling permissions properly depends on the source’s capabilities and the use case we are building to. Knowing that this work will be custom for your business, we are building first-class primitives to model and manipulate permissions throughout the pipeline.
Learn more about our approach to handing permissions and identities here.
Step 2: Normalize
Once we’ve extracted the data from the source, we need to get it into a shape (né schema) we understand. This is a process called normalization. We generally want to prepare data for the downstream steps in a known format - we want all data that looks like a contact from a CRM system (Salesforce, Hubspot, etc) to have the same shape and data types. This will make future transformation easier and composable. We also want to have a spot to deal with API drift from upstream APIs. Finally, in some cases, we will want to merge data from a few streams into one. This is also the step where we validate the data we got from upstream, against an expected schema.
At the end of this step, we’ll have incremental data files in known format, now ready to load into our working database.
Step 3: Load (Datasets)
In a blog post, I talked about the properties a database needs for hybrid search. From this point forward, we’ll be working with our data loaded into a platform like Motherduck, Clickhouse, or Elastic, which, at the time of writing, are some of the best open-source horizontally-scalable candidates for this kind of application. To start, we are working with MotherDuck/DuckDB databases.
The schema for our data in this database is roughly:
{organization}-{workspace}-{dataset}{organization}-{workspace}-{dataset}-{collection}-records{organization}-{workspace}-{dataset}-{collection}-documents
Datasets are the root node of analysis, and are more-or-less 1-to-1 representations of the data in the source system. In Airbyte lingo, datasets are the destinations of an incremental sync. Every time we sync against your source (and we can check for updates on the order of every few minutes), all the new and updated information lands here. This is also the place where sync errors will be displayed if they occur.
From datasets, we build multiple context collections.
Step 4: Build Context (Collections)
Context Collections are the use-case specific filters and transformations of a dataset that are needed to power a specific AI application. There’s a lot to unpack in this definition:
- Filters will remove data from the dataset in this context collection, if desired. This means you can filter a dataset into multiple context collections with subsets of the data.
- Transformations (sometimes called mappings) are the creation of additional columns in the dataset that are derived from the data we already have
A Context Collection is use-case specific. Depending on what you are trying to do, you might take the same dataset data and manipulate it in different ways to get the outcome you want. Different AI/LLM applications tend to do best with different search documents. Or, you might want to bifurcate your dataset based on permissions or access roles. It’s important that datasets and collections stay in sync - as new data is added to the dataset, all the collections related to it need to be updated soon afterwards. Airbyte’s AI studio takes care of this for you.
The context collection is the most novel part of an AI data pipeline, and where we will be spending the majority of our time with design partners. There are thousands of possible manipulations to data which might be desirable, and we are interested in finding the most common patterns and building the tools so you can extend them.
The entire workflow of preparing a record for use includes:
- Filtering
- Transformation / enrichment / applying mappings
- Document creation
- Calculating embeddings
- Evaluations
- Making ready
Before we get into each step, let’s talk about the workflow of the whole process. Airbyte is building a “Context Collection Playground” so that you can experiment in close-to-real-time with each of these steps. In time, you’ll be able to run these steps locally, and check in your work to git. This is where your use-case specific business logic lives, your company’s secret sauce. You’ll also want to compare versions of collections against each other for accuracy, cost and speed. We aim to make this activity easy and fast.
Filtering
The first step is to remove any records from the dataset that you don’t want. Maybe EU data shouldn’t be included in a collection for USA users, or perhaps you want to introspect the permission data which was extracted from the source to make your decisions on what to include (e.g. removing internal users). It’s important to assume that anything that’s in the collection could be leaked by the LLM to the user, so be sure that what you are including is safe. If you have different groups of users with different access rights, make different collections - we make this easy.
Note that this pre-filtering is not the same as search filtering. This layer of filtering is to remove content that no one should see. However, if there’s information that only some users should see (e.g. “show my what meetings I have today”), and you can represent that query with strong guarantees at query time (e.g. where user_id = 123), then you might not need to pre-filter those documents… Thanks, hybrid search!
Transformations and Enrichment
We think there are a few rough categories of transformation folks might want to do to the data in a collection, and we call each of these a “mapper”, and each of these adds a new “virtual column” to your data, which you can then use for future mappers and in the record’s document. The general types of mapper are:
- Removal - You may want to null out a particularly sensitive piece of data so that it is not available downstream or to the LLM.
- Derived - Using the data already present, you may want to compute a new property. For example, you may want to combine first_name and last_name into a new full_name property, or you might want to extract the domain of a user’s email address after the @ sign to guess what company they work for. Today, we provide a Jinja interface to your data with custom filters that make this pleasant.
- API - You might want to enhance your data by hitting an API. There are Enrichment APIs to learn more about users by their email address, or look up if they’ve been banned by your payment gateway by user_id, etc.
- AI / LLM - Passing the data you have to an LLM is a great way to produce summaries, do sentiment analysis, and other non-deterministic tasks.
- Cross-dataset Joins - You may want to join data from one dataset with another, for example adding your internal user_id to your Salesforce data.
- Code - And finally, for any use-case not covered here, we will allow you to run custom code against each record to produce new fields.
Document Creation
Once you have all the data you’ll need, thanks to the previous transformation steps, it’s time to build the search document. This is the text that will be embedded and used for vector/similarity search.
Producing good documents is both an art and science. You want to provide the LLM with the fewest documents with the highest quality that get the job done, but you also want each document to be internally complete. Oh, and each record might need to be broken up into multiple smaller documents to fit in a limited context window. For example, consider a very large PDF of a legal contract you might be interested in searching. The document is 100s of pages long, so you can’t feed the whole thing into some LLMs, so you need to chop it up (a process called chunking). Chopping the document up by section (e.g. via heading) is probably a good starting point, but it’s often the case that the section you are on might not have the full context to explain itself (i.e. not internally complete). If this was a commercial real estate contact, and you were trying to ask the question “who is in charge of repairing the elevators?”, the document chunk would need both the exact text “... and the repair agency will be responsible for preventive maintenance and repair, visiting the site not less than 4 times a year”, and the preamble “Evan’s Elevator Repair Company LLC will be known as ‘the repair agency’”.
Knowing that relevant document creation for a commercial real estate contract probably needs the current chunk, the full tree of section headers, and the preamble is both hard to figure out, and the secret to building a powerful AI application. Building an application which will enable you to iterate quickly and test your results is a big part of what we are building.
Calculating embeddings
Once you have your document built, you need to turn that text into embeddings - a vector representation of the text that can be similarity searched quickly. This is a compute/GPU-intensive step that we make easy and parallelize. There are hundreds of algorithms/models you can choose for this step, and experimenting with the cost and speed of each will be important.
Of note, what you embed probably won’t be the document itself. A section, a summary, or even a representation of the document that was produced by an LLM might produce better results.
Making Ready
Within the collection itself, there’s a lifecycle to consider. Some of the transformations (and later evaluations) might be slow or expensive, especially if an external API is involved. That means that a useful collection needs to serve the current version of a record while the new version is still processing. The collection also needs to be resilient to any errors that occur in the transformation process or retries that are needed when hitting external systems. Airbyte leverages our syncing experience to handle this lifecycle gracefully and expose the metrics you will need to understand this workflow. We deduplicate older versions of the records away as new updates flow through the system and become ready.
Step 5: Evaluate
Like all software, you need to test it to be sure that it works. Because everything above this step was leading up to an LLM using the data, and LLMs can have unpredictable behavior, the only way to know changes are helpful are to test changes against a robust evaluation suite. It’s important that we make this easy, fast, and fun. Testing document creation has a few forms that we will be building out:
- Deterministic testing - Given this query or search, are the proper documents returned
- Scoring - Given this set of transforms and documents, do the results of a search of known content produce better or worse results
- Feedback/voting - Given this set of transforms and documents, are the results our application is providing better or worse, according to our users.
Some of these evaluations can be expressed within a testing framework like pytest, while others require collecting data from users and evaluating after the fact. Testing context documents is both an art and a science.
Step 6: Consume (APIs and Functions)
It is finally time to use your data! Once the everything is ready, the same collection can support a number of interfaces:
- Hybrid search - “What users are in Houston?” can be answered from our Salesforce contacts collection, which may also know to apply traditional filters to only consider records in which the user is active.
- Function calling - “How many users do we have?” is best answered by a COUNT SQL query, and we’ve made it possible to run text-to-SQL and execute the query via a functional interface and agentic workflow.
We can also combine the access to multiple collections and specialized instructions in an “assistant.” These are agents that determine which context collections to use and how to use them based on varied user input.
There are even more ways to consume this data and we can assist in co-designing your applications accordingly!
A Context Collection Example
Putting this all together, let’s walk through an example.
The use-case is the same as above - we would like to build an AI copilot for our sales team, using our Salesforce data. We are starting with two use cases in mind:
- We want a chat interface (co-pilot) to use mid-call to ask questions of the prospect’s account (e.g. “when was our last contact” or “how much did you pay last year in your contract”... or even “Is customer X likely to churn?”)
- We want an application interface for the manager to understand the status of all the deals in flight (e.g. “how many deals are open now that are likely to close by the end of the month?”)
I’ve chosen these two examples because one operates on specific data about one object (the prospect’s history), while the other operates on a set or aggregation of all the data in the collection. The first use case could be solved by RAG, and the second with a SQL function call. The table below ties the above concepts together and shows what an AI pipeline for this application might look like.
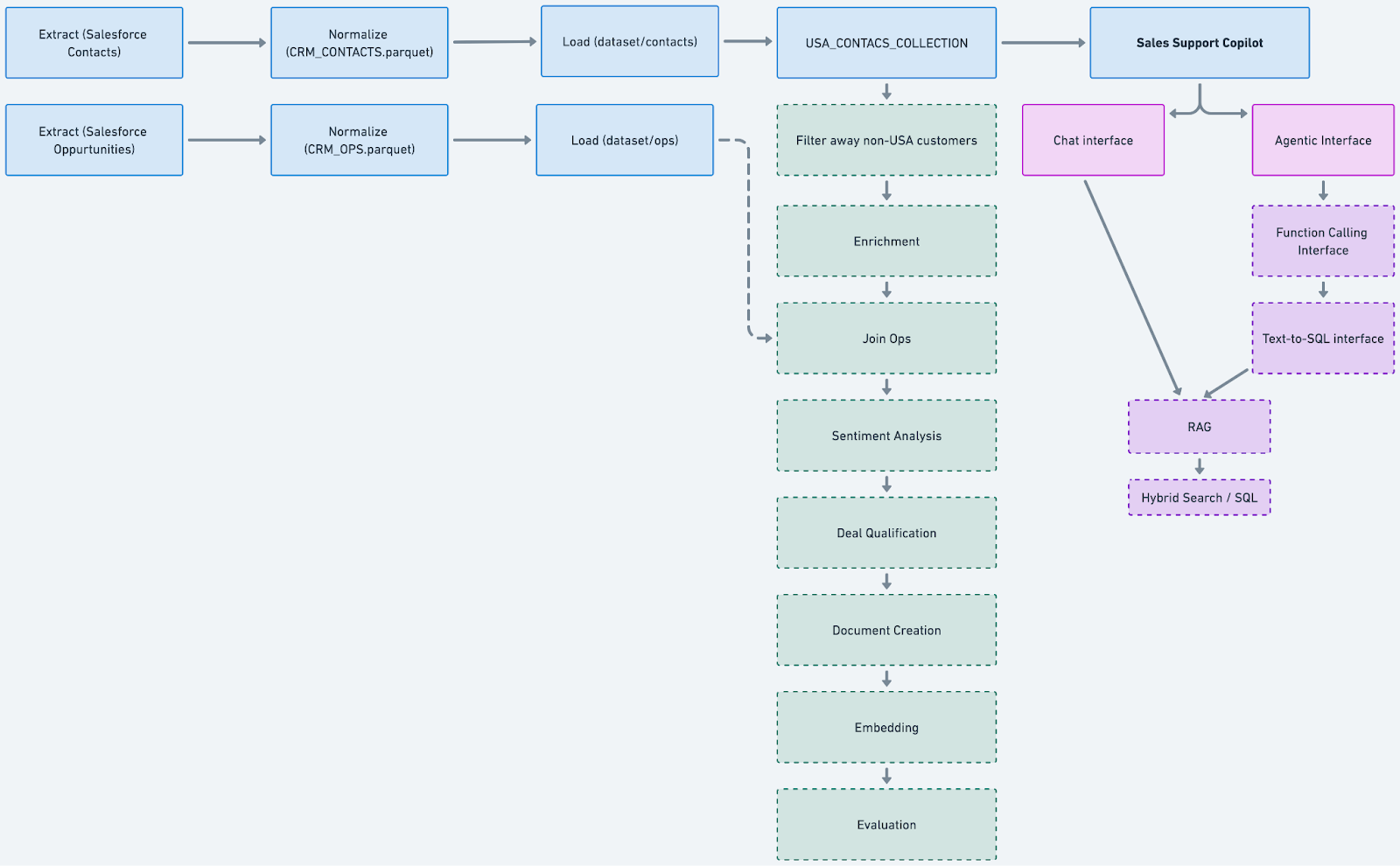
RAG
At the end of the Build Context step, the documents we create from our Salesforce data in the USA_CONTACTS_COLLECTION could look something like this:
# Contact: Evan Tahler
## Details:
* Email: evan@airbyte.com
* Phone Number: 123.456.7980
* Role: Director of Engineering
## Company Details
* Airbyte
* Address: San Francisco, USA
* Website: http://airbyte.com
## Product Interest
Airbyte Cloud
## Opprtunity Status
* State: Open
* Estimated Annual Contract Value: $100
## Other Comnpany Contacts
* Frank
* email: frank@airbyte.com
* role: account manager
* Sally
* email: sally@airbyte.com
* role: CEO
## Interactions:
1. Cold Call
* Summary: cold outreach, customer showed interest and wanted more product details.
* Next Step: Call next week
2. Sales Call
* Summary: call went well - customer wants pricing info customized for them.
* Next Step: email in new year re pricing
These documents are then embedded and stored alongside the traditional columnar data that provided this information - an opportunity-name and deal-status column would exist as well. Of note, we’ve taken relational data from a few Salesforce APIs and combined it into a document - LLM’s preferred format.
The chat interface works via RAG. During the sales call, we might ask our chatbot “who else have we talked to at Airbyte”, and it would find the document above and pass that as context to the LLM, which would then extract the useful information we asked for -”Frank and Sally”. You can learn more about how RAG and Hybrid Search work in our previous blog post, but in a nutshell, we are asking the database to find documents similar to the keywords in our question, to then pass to the LLM to sort through - letting the LLM judge what is relevant from the context provided in this document. The RAG query will likely provide not only the right document, but probably some false-positive’s as well (e.g. if the notes from another call mentioned “Airbyte”, or perhaps if another company name is similar). LLMs have powerful reasoning capabilities to sort though this… if they are given the data.
Tools
The manager’s question is a little different - “How many opportunities are currently in the open state”. This is a question that can’t be solved by RAG alone, as reading every deal would be required, and that won’t fit into the LLM’s context window… and we want an exact numerical answer here, not a summary. This is where tools come in. Tools provide “APIs” or “functions” to allow the LLM to ask a third party service for information. Tools self-describe when they should be used, and their inputs and outputs. Airbyte provides a text-to-sql interface over all of the collections we build for exactly this purpose.
Visualizing a tool definition looks something like this:
tool:
* Name: text-to-sql for collection "USA CONTACTS"
* Description: When asking for specific counts or
other aggregations of data pertatining to salesforce
opportunities in the USA, use this tool. The schema of the table is:
* id: integer
* document: text
* deal_status: text
...
* inputs:
* agregation: enum[count, average, sum]
* aggregation_column: choose from the columns in the table's schema
* column_filters: what should the aggregation_column be filtered on
* output: number
The information above is enough to allow the LLM to do a few things:
- Decide when to use the tool. It now has enough context to know that if the user is asking for a “count” or "aggregation" and to try calling this tool. Otherwise, it might choose another tool (RAG search is also expressed as a tool), or be able to answer based on its training data or the messages already present in the conversation.
- The tool’s input is described so that the LLM can keep asking for more data from the user until satisfied. In this case, [count, deal_status, open] would be the inputs, leading the tool to eventually run the query select count(*) from collection_table where deal_status=”open”.
- The tool’s output is described as well, so that the LLM can format a reasonable response, e.g. “there are 7 open deals”.
As the collection provides multiple tools, including RAG search and SQL function calling, a rich interaction can take place where the manager can ask for more information about those deals, and the LLM can switch over to loading the relevant RAG docs when asked.
Summary
The goal of an AI Context Pipeline is to extract and prepare data into a format that is appropriate for multiple LLM use-cases. This includes document creation and embedding, but including what you need for additional analysis and tools is also important to build robust and powerful AI applications. If you are interested in learning more about how Airbyte can help you with these pipelines, please reach out!

I write about Technology, Software, and Startups. I use my Product Management, Software Engineering, and Leadership skills to build teams that create world-class digital products.
Get in touch